This event was today at Excel in London. It is handily co-located with Cloud and Smart IoT events, which was a major draw for me, as I am not strictly speaking a data/IT guy, more of an analyst and wannabe subject matter expert with IoT and increasingly cloud within my professional interests. As the write up is quite long the following list of links lets you jump to the summary of the relevant presentation:
I did start from the Cloud Expo end of the room as there was a whole 'theatre' devoted to talks on software defined networks. Judging from the first presentation which looked at SD-WANs, these guarantee the exact opposite of net neutrality to business users, prioritising cloud business applications at the expense of e.g. YouTube traffic. The technology involves 'aggregating and orchestrating' a variety of links of varying performance and availability from MPLS and 3G to old school internet, and intelligent path control for different applications' traffic, e.g. routing VoIP traffic through MPLS, thus being able to guarantee QoS above 'best effort'. Interesting ideas on SLAs for application uptime and even application performance could extend the current SLAs of network availability. To my simplistic brain, it would all be simpler and safer if we keep most applications offline and standalone, instead of putting everything on the cloud, but there's a cloud enabled industrial revolution in progress, which involves cost cutting and getting rid of half the IT department. Clearly that is the main driver, with the downside being increasing demands on the network.
In complete contrast, I moved on to a presentation in the Big Data World area on the
General Data Protection Regulation. This made me feel suddenly quite nostalgic for the good old EU, its much maligned courts and the human right to a private life. The
list of non EU countries that conform to european data protection standards is interesting to say the least: Andorra, Argentina, Canada, Faeroe Islands, Guernsey, Israel, Isle of Man, Jersey, New Zealand, Switzerland and Uruguay. Maybe there's material there for a tableau map and some spatial insights!
Next was SelectStar, a database monitoring solution. Their main selling point is being a single monitoring tool for all database technologies, as increasingly companies will have a mixture of open source and proprietary relational and NoSQL solutions, rather than be an e.g. 'all Oracle' house. I was hoping to get some tips on actual monitoring of the health of a Hadoop cluster, but they don't do much in addition to what the built in Hadoop monitoring tools offer, in fact Hadoop is quite a recent addition to their offerings.
I try and balance attending presentations relevant to my job to things that are just plain interesting. In the spirit of the latter, I went to the 'deep learning' keynote, which as one member of the audience noted, was using mostly image recognition examples. The presenter explained that they make good presentation material, and the technique has wider applications. The key thing I took from this was that the feature extraction is now also 'trainable', whereas in old school machine learning only the classification stage was. I'm not fully convinced machines are better than humans at deciding what the best feature vector is, and I should read up on any speech/music processing applications of this as I have a better theoretical grounding in that field. Would a machine ever come up with something as brilliant but crazy as the
cepstrum?
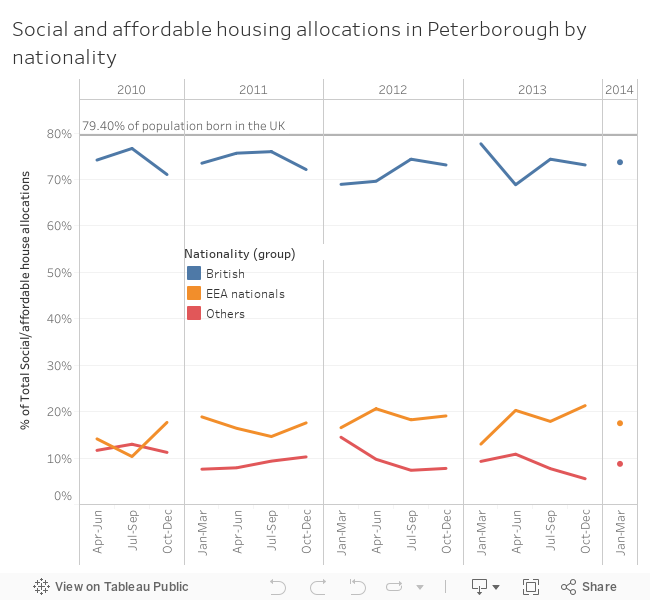
I next attended a talk on deriving 'actionable insight' from data. This is now such a cliche that is a bit meaningless, especially when the whole brigade of viz whizz kids are into dashboard visualisations with little accompanying text, carrying little of the insight a well illustrated text heavy report will give you. Refreshingly, and perhaps tellingly on the differing priorities of the private and public sector data world, the speaker used no visual material whatsoever. He just talked about his work as a data analyst for Peterborough city council, and projects such as identifying unregistered rental properties by fusing a variety of datasets including council tax and library user details, or analysing crime patterns! I should look into what open data offerings they have.
The weather company, finally a (nearly) household name, was next, in a keynote on weather for business. They interestingly
crowdsource some of their data to achieve 'hyperlocal' resolution of 500m, 96 times a day globally, while a major sector of their corporate customers, airlines, are also data providers. They have a unique data processing platform and the speaker did put a certain emphasis on their acquisition by IBM and the 'insights and cognition' synergies that will result from it.
I then ventured into the Smart IoT area for a talk from O2/
Telefónica. The data protection theme was present here again as they make sure their data is secure and anonymous via aggregation and extrapolation, and a certain amount of weeding out of any data that is not aggregated enough and therefore could be used to identify individual users, and users consenting to the use of their data also came up during question time. They derive location via both 'active' (calls) and 'passive' (cell handovers) means, as well as behavioural data from apps and websites visited, and 'in venue' information from their wifi hotspots and small cells (another hint at the seamless integration of multiple networks mentioned earlier). This builds up to 6 billion events on a typical day, and they keep an archive of 4 years. These events are classified into 'settles' and 'journeys', analysed to identify origins and destinations, with uses ranging from transport planning, audience profiling, retail decision making etc.
Back to the other end of the hall to hear
self professed ubergeek Andi Mann of Splunk on DevOps . Follow the link as he can summarise his ideas much better than I can. He gave me another interesting fact on
Yahoo's past as a cool tech parent company, despite today's headlines on security breaches: the presentation on
dev and ops cooperation at Flickr that was key to starting the devops conversation back in 2009. I think the idea of devops has applications outside software, in fact a lot of the operational intelligence work I do sits somewhere between operations and product/service development.
I did skip the QlikView presentation for the sake of Splunk, but came back to the Big Data keynotes for Esri. Their presentation focused on the benefits of spatial analysis, giving
the grid aggregation I wrote about in the past as an example, along with navigation, fraud transaction detection and even insurance for ships going into pirate infested waters!
Finally a joint act between Wejo and Talend on their connected car project. This was interesting for many reasons, from the technologies involved on the car such as
eCall to the technology used for data processing, as Talend offers an open source ETL tool that can sit on top of Spark. On that latter front there was a certain emphasis on the benefits of having a unified infrastructure for batch processing and streaming, and a mention of the
Apache Beam project as something Talend will support in the future to that end.
In the time left between all this I got to talk to some of the exhibitors. The most intriguing one was a Belgian company who make
Anatella, which would catch the eye of anyone working in telecoms for their binary CDR processing capability. The demos included some fascinating social network graph analysis derived from phone calls: e.g. flemish speaking belgians tend to call other flemish speaking belgians and french speaking belgians tend to call other french speaking belgians, with the exception of Brussels, which proves to be bilingual territory not only in constitutional theory but also in telephony practice! There was a news story a few years ago on similar telephone 'connections' between UK regions, I remember Wales being split in three north to south, with more contact with the corresponding adjacent english region to the east than the rest of wales north and/or south. Fascinating work that can escape the narrow confines of marketing into proper Geography research, not unlike the work of the
Flowminder Foundation that I link to on the right.