Let's now consider a data source similar to the contracts, where there is a duration instead of an end date. Easy: we can get the end date with a calculated field. The problem then is we are not given the option to use calculated fields in pivots.
This was a big disappointment for me back when
pivots appeared in version 9. I had data in the format above, a python script to do the end date calculation and the pivoting and I was hoping to retire the script.
I then went to one of the tableau conferences on tour in London. There I learned that you could copy some data in a visualisation, and paste it in a new worksheet, creating a new source from the clipboard. This was useful, and by using this I found a way to do pivots with most fields, as long as they could be expressed as measures. This is very dodgy and I don't recommend it, I should really stick to the Python script. But here is how to do it:
First of all convert your dates into numbers, as dates can only be dimensions, not measures. Use something like:
datepart('day',[Start Date])*1000000+datepart('month',[Start Date])*10000+datepart('year',[Start Date])
Then create a view with measure names and measure values showing these 'measure' dates with all other info as a dimension.
Finally select all the rows, copy and paste into a new worksheet. Caution: This doesn't work in Tableau Public! If done in Tableau Desktop you get this:
Note how there are two Measure Names and two Measure values, the italics ones are automatically generated, the non italic are fields in the clipboard source, string for the names and number for the measures. So now we have our pivoted field name and field value, and can use calculated fields to restore the dates to a date format as well as recreate our increment calculation
DATE(dateparse('ddMMyyyy',str([Measure Values])))
if [Measure Names]='start' then 1 elseif [Measure Names]='end' then -1 end
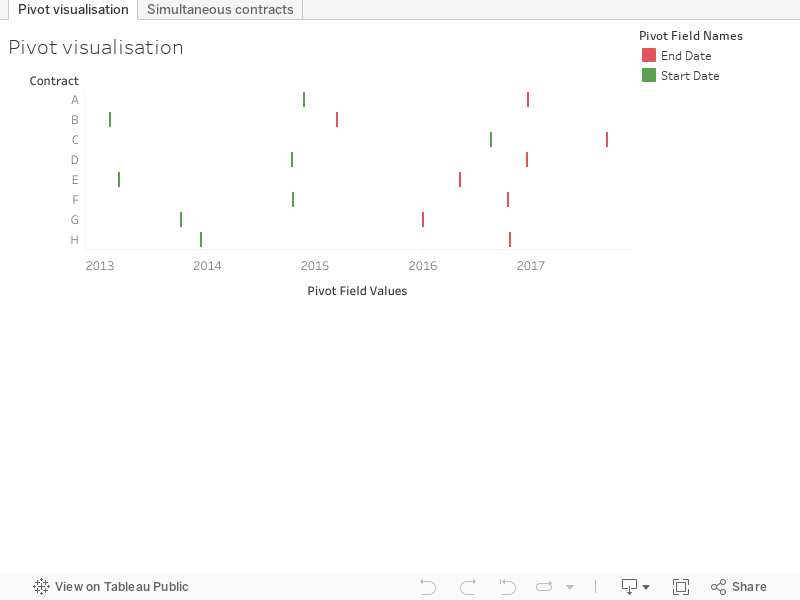
Finally here's the workbook: